Flickr(www.flickr.com) 是国外一个领先的图片分享网站,现在应该在yahoo门下,感觉yahoo还是有很多好东西,奈何资本要抛弃他了。这个轮回其实挺有意思的,起先是做实业 被microsoft郁闷了,说软件是虚的值不能那么多钱,然后microsoft被yahoo郁闷了,说互联网是虚的不值那么多钱,然后是yahoo被 google郁闷了,yahoo比较厚道没说什么,现在microsoft要收购yahoo了(折腾好久了,估计要落听了吧),不知道google将来要 被谁郁闷了。成功建立在相同的失败上,反过来失败都是建立在相同的成功上也成立,进入正题吧。
原文地址是http://highscalability.com/flickr-architecture,本文不是原文的严谨翻译,带有我的理解以及补充,由于水平有限,文中的错误请各位斧正。
Flickr处理的数据:
-
多达40亿次的请求(http request or database query?不知道了,不管是哪个,都够大的吧。)
-
squid总计约有3500万张图片(硬盘+内存)
-
squid内存中约有200万张图片
-
总计有大约4亿7000万张图片,每张图片大概4~5MB
-
每秒3,8000次请求 (存储了1200万对象在里面)
-
2 PB 存储(星期天要消费~1.5TB)
-
每天新增图片超过 400,000
Flickr用到的技术:
-
PHP
-
MySQL
-
Shards
-
Memcached 作为中间缓存层,memcached在web2.0网站中可能是引用最广泛的产品之一,开源&强大.
-
Squid 作反向代理服务器(reverse-proxy for html and images).
-
Linux (RedHat),如果你想用RedHat企业版又不想付费,试试这个CentOS,基本上100%克隆RedHat企业版(估计传说中1%的RedHat代码没有),我用的就是这个。
-
Smarty 作为模板解析,很多人在讨论smarty这不好那不好,但是大网站都在用,稳定而且功能强大,系统的瓶颈从来不会再smarty这里,我保证。
-
Perl 估计用perl做一些系统层面的东西吧,比如日志处理(猜测)
-
PEAR 做XML和Email解析,和我们一样,Flickr用的也是PHP4,不过新项目还是用PHP5吧
-
ImageMagick 图像处理的不二选择
-
Java, for the node service,Java就不太了解了,希望读者补充
-
Apache 大家都在用,尝鲜的用户nginx或者lighttpd(适合静态文件,youtube用它做媒体文件服务器),出了问题你会抓狂的。
-
SystemImager 作为服务器部署
-
Ganglia 分布式系统监控,或者你可以试试nagios,据我所知也很多公司在用
-
Subcon 用SVN维护服务器配置文件并且可以部署不同的配置文件到服务器集群中去(这个我没用过,系统运维的可能会喜欢)
-
Cvsup 文件分发,是否类似rsync?
-
Wackamole前端负载均衡,类似的产品有http://haproxy.1wt.eu/
Flickr架构
常见的Squid反向代理、PHP App Servers、Net App’s、Storage Manager我在这里就不讲,我们关注一些让人兴奋的特征:
-
Mysql的Master-Master结构,mysql的常见的master-slave结构,大家都知道存在”single point of failure”(单点故障的问题),且只对读操作有好处,对于写频繁的网站却不是一个好的解决方案,Flickr的双master方案据我推测用的就是 这个http://code.google.com/p/mysql-master-master/,原理就是master轮询,保证同时只有一个master负责写,解决了单点故障的问题。
-
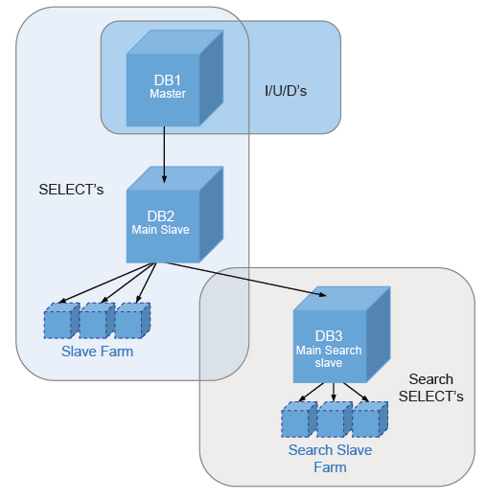
Dual Tree Structure,看看下面的图就知道什么是“双树结构”
示例图中上方的2台机器为master,下方的4台为slave,这种“双树结构”的设计保证一个slave只有一台master,易于扩展也不会形成环路。原文中说这种设计是1+1=200%的设计,简单高效。为了防止自增长冲突,数据表中无自增长列。
补充:对于大型应用的分表设计,防止自增长冲突是个问题,有个简单的方案:比如分3张表,可以设第一张表从1开始以3跳跃递增,那么第一张表存储的序列为 1,4,7,10……,第二张表从2开始也以3跳跃递增,第二张表存储的序列为2,5,8,11……,第三张表从3开始以3跳跃递增,第三张表存储的序列 为3,6,9,12……,保证不会有重复的序号,但这种方案的缺点是如果数据爆炸,3张表不够,你分4张表呢?需要手工迁移数据,如果程序写的不好,底层又要大动了。
Flickr采用的方案是一个中心’users’ table(用户表),记录的信息是用户主键以及此用户对以的数据库片区(有点类似Key->Value的设计,这样的数据结构查询起来是非常迅速 的,据说Google的用户登录数据用的就是这样的设计,通过改进版的BDB数据库存储用户名和密码,这样登录起来就不用去查那个大表了),从中心用户表 中查出用户数据所在位置,然后直接从目标位置中取出数据。
-
用专门的服务器存储静态内容,这个容易做到,比如专门的图片服务器。
-
“Use a share nothing architecture”这个比较费解了,字面上的意思是使用一个无共享的架构,其实就是解除架构上的依赖,类似我们写程序解耦合一样。
-
除图片外,所有的数据都存在数据库中,这里他们提到了PHP session,我们知道php的session是存储在服务器文件系统的,而且默认没有做hash目录,这就意味着如果你的网站访问量大,比如有10万 个人在线,你的session目录下就有10万个文件,如果你的文件格式是NTFS(windows)或者Ext3(Linux),你要定位到某个文件, 系统基本上会假死,有个好的建议是不要在一个文件夹下放超过1000个文件。使用默认的php session还有另外一个问题:服务器session同步,用户在A服务器登录后,session存储在A服务器上,然后应用跳转到B服务器,B服务器 上的session没有同步就出问题了,当然解决这个问题的方法很多,比如统一存储session,所有服务器的session都存储在一个vfs设备 上,或者通过cookie重新生成一个session在B服务器上
Flickr的架构不能说是完美的,没有完美的架构,ebay对于扩展有以下建议:
-
不要预先去为性能扩展,出现问题之后找到问题再寻扩展;
-
不要想寻找到一个一劳永逸的方案,因为你不知道下一个瓶颈在哪里;
-
访问量大了,出了问题,修改架构,稳定运行,访问量再大了,又出问题了,再修改,这个是解决问题的唯一方案。
Flickr是Lamp架构比较成功的案例之一,抛出Flickr的架构是因为看到国内很多的架构设计盲目、迷信以及短视,不过相对于架构来说,程序的结构更让人担忧,后面的我会写一些关于程序结构的文章,希望能和大家一起讨论成长,好了,我们继续Flickr的架构。
-
“Statelessness”设计,原文用的是这个词,字面上的意思是“无国家的”,看了一些相关文档,我觉得 Statelessness的含义是“无界限的”设计,一个简单的例子,现在很多架构设计用到分表,比如用户信息表,怎么分呢?直接hash分表,两张表 就按奇偶分,n张表就按n的模进行分,这种设计就是Statelessness的反向,你把你的用户绑定在一张固定的表或者固定的机器上了,如果你的用户 里面有付费用户,你希望把他们的数据单独存储或者用专门的机器处理,你怎么办?你设计的太死了,你的付费用户只能和免费用户绑定在一起,提供一样的服务器 支持,当然,你可以骗用户说他们的服务是有差别的。
-
通过master-save的设计能解决一部分问题,但很快你就会发现不行了,常见的master-slave只能解决读的问题,但存在单点失败故障,而且当负载比较重的时候会存在复制延迟的问题,很多公司都会碰到。
-
搜索功能由专门的服务器群来支持,通过复制需要搜索的内容到搜索服务器去搜索,和App servers分开。
-
集群
-
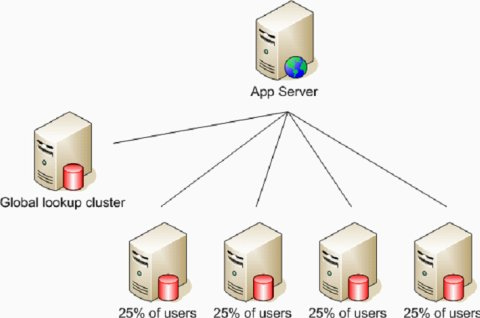
分表:按照一定主键拆分数据表,比如按照用户划分;
-
一个用户的所有信息在同一组服务器上
-
数据能够在不同的服务器组上迁移(Statelessness)
-
一组中心服务器负责查询,比如定位某个用户在哪个服务器组
-
不要以用户ID作为分组的依据(Non-Statelessness)
-
服务器组中每台服务保持50%的负载,当某台服务器down机或者维护时,另外一台服务器100%负载
-
访问高峰时,每台服务器的负载可能高于50%,现在Flickr通过增加服务器来让服务器负载在50%以下
-
每个页面大概有27~35个mysql query(够高的),点击数统计、API调用数据库都是实时的(太恐怖了,估计只有Dathan Pattishall会这么变态的使用mysql)
-
每组服务器处理40万+的用户数据,很多数据存储了双份,比如A用户对B用户的博客进行了评论,那么评论的数据在A的数据表里面和B的数 据表里面都存储了一份,Flickr通过事务来保证同步。(这样做的目的是保证同一个用户的数据都存放在同一组服务器上,省去复制的成本。)
-
Flickr的硬件设置:Intel EMT64处理器/红帽RHEL4/16GB内存/6块15000转的硬盘做RAID-10/12TB用户数据(仅仅是数据库而不是图片)/2U服务器,每个服务大概有120GB数据
-
备份:每天不同时刻跑cron,每天晚上做数据库快照,专门的服务组来备份(和线上业务分开),交叉备份(比如每天、每周、每月)
-
每张图片都有自己的档案,档案包括大小、尺寸、像素等等,储存在数据中
-
每组服务器最多400个连接,45个线程缓存
-
Tag标签,Flickr发现常见的数据库结构不能很好的处理巨大的标签库,他们采用的是类似倒排索引以及大量的缓存来处理,并且Tag标签不是实时的,他们会在线下进行统计
-
Flickr目标是所有的事务都做成实时的,没有延迟(个人觉得倒是没有这个必要)
Todd Hoff总结的经验:
-
不要把你的应用简单的看成一个Web应用,可能会有REST APIs, SOAP APIs, RSS feeds, Atom feeds等等的应用
-
“无界限”设计,不要把你的用户死死的绑定在某个服务器上
-
产品设计时需要做扩容的计划以及预算
-
慢慢来,不要一开始就买一堆服务器
-
实地考察,不要臆想,获得实际数据之后再做决定
-
内建日志系统,记录服务器和应用日志
-
Cache,缓存是必不可少的
-
抽象层,由于你的架构随时可能变,架构的变化必定要带来底层的变化,这就需要你在底层的基础上根据业务封装一层中间层,这样底层的改动不至于影响业务(这个太重要了,不要因为扩展把原来的程序推倒重来)
-
迭代开发,随时改进
-
忘记那些调优的小技巧吧,比如很多人对与PHP里面的require和require_once的性能差别,这些性能的差异和架构上的短板比起来根本不足为道
-
在线上测试你的效果
-
忘记用工具测试出来的结果,这些结果只能给你一个大概的印象而已
-
找出你的系统短板,一台服务器的最大处理能力是多少?现在离最大负载还有多远?mysql的瓶颈在哪里?是不是磁盘IO?memcache的瓶颈在哪里?CPU还是网络传输?
-
注意你的用户使用规律,比如Flickr发现每年的第一个工作日比平时多20%~40%的上传量,周日的访问量比平时要多40%~50%
-
要注意指数型的增长
-
你的计划是为你访问的峰值设计的
补充:阅读完原文的评论,有一个评论翻译出来给大家分享:
Flickr如何存储图片的呢?
标准的Flickr图片Url是这样的http://farm1.static.flickr.com/104/301293250_dc284905d0_m.jpg,其中farm1是Flickr的服务器群,static.flickr.com是 Flickr静态图片服务器,104是服务器ID,301293250是图片ID,dc284905d0是Flickr的加密串,防止盗链,m表示图片的 尺寸。m表示中等尺寸
后记:
终于“翻译”(姑且用这个词)完了,看到原文的一个评论 是”Hmm… i can not beleive flickr written on php…”,借用好像也是Flickr的人说的一句话:扩展的不是语言,而是架构。国内很多大的企业都在用PHP(比如我所在的sina),PHP总给人是草根语言的感觉,是因为没有人肯分享自己的架构,以及程序员写程序的时候不注意自己的结构(设计模式),好的架构只能让你的程序跑的更快,好的结构让你 的程序更易于维护,更容易让别人看的懂,更容易团队合作。
|